求助2文本交集取不相同的删除相同的
功能说明:本程序是一款基于易语言开发的图形界面应用软件,主要用于处理和分析纯文本数据。通过分析其源代码逻辑,该程序集成了文本初始化配置、多模态内容比对以及敏感词过滤三大核心模块,旨在解决文档去重、内容查重及文本清洗等自动化处理需求。
以下是程序各功能模块的详细总结:
### 1. 程序初始化与基础设置
在窗口加载完成的事件(`__启动窗口_创建完毕`)中,程序预设了基础的环境变量(如`#文本1`、`#文本2`),并将初始化值预置到相应的编辑框(`编辑框1` 与 `编辑框2`)中。这表明软件启动后会进入待机状态,等待用户调整输入内容以便触发后续的处理流程。
### 2. 行级文本一致性比对
通过监听 `_按钮 1_被单击` 事件(代码中存在多段同名过程定义,体现了不同的比对策略),程序实现了深度比对功能:
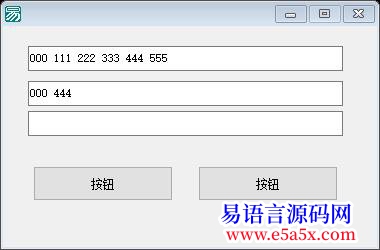
- **分割逻辑**:程序支持以“换行符”为单位,将两个编辑框内的长文本分割为独立的行数组。
- **交叉验证**:采用双重循环(嵌套 `计次循环`)遍历两组行数据,当检测到两篇文档中存在完全一致的段落或句子时,将匹配到的内容输出到结果显示区(`编辑框3`)。
- **应用场景**:此功能特别适用于快速排查文档副本、比对两个版本的合同条款一致性,或在大量信息中筛选出共用的标准段落。
### 3. 词级筛选与文本清洗
代码中还包含了更为细粒度的词法处理逻辑(对应第二处出现的逻辑块及 `_按钮 2_被单击`):
- **分词与过滤**:程序不仅支持按行处理,还具备按“空格”或其他分隔符进行分词的能力。它将主文本(通常为待处理长文)与样本库(通常为待过滤词单)进行原子化的逐一匹配。
- **动态剔除**:一旦在样本库中发现匹配项,主文本中将相应移除这些内容(利用 `子文本替换` 或直接不追加的方式)。这部分逻辑实质上构建了一个“反义”处理器,常用于在发布内容前,依据“白名单”机制清除广告语、重复无意义字符或特定的敏感术语。
- **容错与边界处理**:代码中包含了对末尾空格的预处理(确保字符串尾部衔接自然),保证了文本连接时的标点与空格规范性,提升了生成的可读性。
### 4. 总结
综上所述,该程序并非单一的编辑器,而是一个轻量级的**文本数据挖掘与预处理辅助工具**。它巧妙地利用了易语言的可视化编程特性,通过组合使用字符串分割、数组遍历及条件分支语句,解决了非结构化文本中的人工校对痛点。无论是对比两段文章的雷同度,还是从一篇长文中智能剔除特定的“脏数据”与冗余信息,本程序都能提供高效的自动化解决方案。对于需要进行批量文章修改、SEO 内容降重或建立基础数据库的应用场景具有较高的实用价值。


======窗口程序集1
| |
| |------ __启动窗口_创建完毕
| |
| |------ _按钮1_被单击
======窗口程序集1
| |
| |------ _按钮1_被单击
| |
| |------ _按钮2_被单击
注:本站源码主要来源于网络收集。如有侵犯您的利益,请联系我们,我们将及时删除!
部分源码可能含有危险代码,(如关机、格式化磁盘等),请看清代码在运行。
由此产生的一切后果本站均不负责。源码仅用于学习使用,如需运用到商业场景请咨询原作者。
使用本站源码开发的产品均与本站无任何关系,请大家遵守国家相关法律。